I enjoy baseball and was glad when the lockout finally ended. Like many other people I soon found myself constantly refreshing the MLB website for the updated game schedule which is probably why this happened:
But what I actually wanted was the Mariners schedule as a CSV to make it easier to filter and sort to figure out which games I could go to this year. Last year I wrote a script to do just that for Mariners games and now seemed like a good time to add a few more features I wanted:
- enable usage for all MLB teams
- make it pip installable for better distribution
- have a nicer interface –
$ mlbcal <command>instead of$ python ./script.py <command>
The end result was mlbcal. This post is a brief explanation of the project design and some things I learned along the way, mainly around packaging.
schedule endpoint
Both my original script and mlbcal center around the MLB Stats API schedule endpoint:
https://statsapi.mlb.com/api/v1/schedule
At a minimum it needs three parameters:
teamIdstartDate- dates are expected in MM/DD/YYYY formatendDate
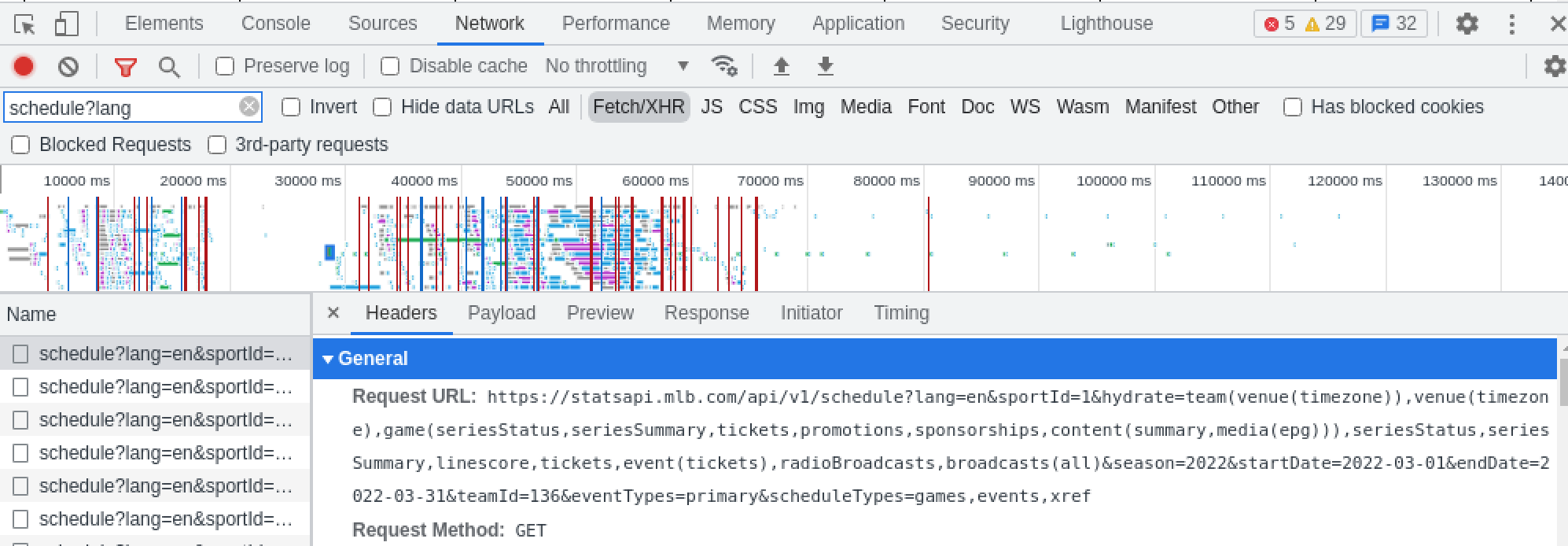
It outputs out a list of days and within each day a list of games and the original script unfurled this into a flat structure. By default it includes pre, reg, and post season games. I was able to figure out the Mariners teamId (136) by using the Network tab of the Chrome Dev-Tools console while viewing a page on the MLB Mariners schedule. As you can see from the screenshot the endpoint can take many more parameters but I wanted to strip it down to the bare minimum for simplicity.
team endpoint
I was able to isolate the teamId for my home team but the main thing I wanted to add was support for all teams. This meant creating a team name to team id lookup table but I wanted to avoid complicated name parsing logic if possible. I intially considering creating this list manually, which would have been tedious but doable, but after poking around the MLB-StatsAPI wiki I found the teams endpoint:
https://statsapi.mlb.com/api/v1/teams
It needs a minimum of two parameters:
sportId- The default value is 1 which probably = MLB. I’m not sure what the other values are.season- the year of the season in YYYY format
This returns a json list of teams with a lot of info but the main things I needed were the teamId and different representations of the team names. After some trial and error I settled on parsing out these: abbreviation, teamCode, clubName, and shortName.
This was then converted into a json dict of teamId -> list team names (lowercased) and saved in the repo. The team lookup function loads the json file into memory and iterates through all keys, returning the key for the first result where the input search value is in the list of team names. I was fine with the looping method rather than something more performant because it was easy to write and understand and in this case n=30, so no need for optimization.
So in practice you could look up “CWS”, “CHA”, “White Sox”, or “Chi White Sox” (case insensitive) and they would all return 145 as the teamId. It’s not 100% name coverage but I think it’s good enough especially since it includes the two common three character abbreviations. Plus it has the benefit of being easy to update by re-running the utility script if new teams are added to the league in the future.
Note: I found a bug while writing this post where three pairs of teams shared the same franchiseName value: “New York” for NYA/NYN, “Chicago” for CHA/CHN, and “Los Angeles” for LAA/LAN. I publishing a fix that removed franchiseName from the list of parsed out team names to eliminate this ambiguity.
final design and organization
I settled on a command line interface that got the team input from the user, translated that into a teamId, generated and requested the schedule endpoint url with the given teamId and the full year as the start and end dates, and then return a trimmed version of the output either as json or csv to stdout which needs to be redirected into a file by the user. This last part was to avoid writing code that opened and saved files and thus further reduce code complexity.
In terms of code organization after some initial missteps with OOP design (scope creep!) I opted for a barebones approach. I the logic and parsing in main.py and put anything related to creating or reading the teams.json lookup file into a utils folder. I also added a download function within utils/download_teams.py to be used in both the utils functions and main.py. It is a replacement of requests.get using urllib to remove all external dependencies. In retrospect I would have left in the requests because the location of this shared download function is confusing (it’s not a util if main.py uses it directly) and requests is a light dependency. That said, the package has no external dependencies as it is written now.
packaging problems
My main struggle with completing this project was packaging. Up until this point my experience with packaging was for internal teams so I never used PyPI to open source a project and I avoiding building distributions by having users install in editable mode (pip install . -e). My main reference for figuring this out was the Packaging Python Projects documentation. It was incredibly helpful for guiding me through the process and I highly recommend it.
Here are some helpful things I learned during the packaging process:
- Constantly running into
ModuleNotFoundErrorwhile testing locally? Add your project path to your PYTHONPATH in your bashrc/zshrc file. I never really knew what this was for and started testing out path manipulation before I figured out it was for testing out a project, with internal imports, before you’ve pip installed itexport PYTHONPATH="${PYTHONPATH}:/Users/you/path/to/project/"
- importlib is a cool way to import and use files within your package (built-in as of 3.7). I originally was trying to use pathlib which was the wrong way to do it because it is relative to your current location instead of a fixed package location
- You can most likely use setup.cfg instead of setup.py. This is confusing because a lot of tutorials demonstrate setup.py because it was the defacto for so long but the new way is setup.cfg unless you need python logic in your setup script (you probably don’t)
- Extra non-code files will not be included in your dist/ folder by default (teams.json lookup file in my case) but you can specify to include them in the MANIFEST.in file
- TestPyPI is a test instance of PyPI with separate login credentials. Upload your package there first and try to install from there before you upload to PyPI
- If you fix some bugs after uploading to TestPyPI and want to re-upload (same goes for the official PyPI), you need to remember to do two things:
- increment your project version in setup.cfg – I forgot to do this many times :(
- rebuild the distribution
- After installing twine, configure your .pypirc file with credentials for both TestPyPI and PyPI. Or better yet create creds scoped for specific projects. In my case I created a
[testpypi]entry for anything uploaded to that and then I created a separate[mlbcal]entry for the official PyPI just for this project. Here’s an example for uploading to TestPyPI:$ python -m build– build dist files$ python -m twine upload --repository testpypi dist/*– upload current folder dist files to TestPyPI
summary
Putting together a simple project like this was a good hands on way to learn how to package and publish a Python project and I recommend this approach to anyone wanting to learn it. Definitely reference the official docs while you’re doing it as they are very helpful. It was also interesting dealing with scope creep in a non-work project. I think having a sense of urgency (i.e. baseball season starting soon) with the release timeline helped me quickly decide which additional scope items I should keep and which were just pushing back the release.
links
- https://github.com/joeeoj/mgames – original script
- https://github.com/joeeoj/mlbcal – mlbcal GitHub repo
- https://pypi.org/project/mlbcal/ – mlbcal PyPI
- https://github.com/toddrob99/MLB-StatsAPI/wiki – wiki for the MLB-StatsAPI Python package
- https://packaging.python.org/en/latest/tutorials/packaging-projects/ – Python packaging docs
- https://packaging.python.org/en/latest/guides/using-manifest-in/#using-manifest-in – docs on MANIFEST.in